Usar Google Drive como CMS
Vamos a recorrer el proceso técnico de conectarse a la API de Google Drive para obtener contenido en un sitio web. Examinaremos la implementación paso a paso, así como también cómo utilizar el almacenamiento en caché del lado del servidor para evitar los principales obstáculos a evitar, como los límites de uso de API y los enlaces directos de imágenes. A lo largo del artículo se proporciona un paquete npm listo para usar, un repositorio de Git y una imagen de Docker.
¿Pero por qué?
En algún momento del desarrollo de un sitio web se llega a una encrucijada: ¿cómo se gestionan los contenidos cuando quien los gestiona no tiene conocimientos técnicos? Si los desarrolladores gestionan el contenido de forma indefinida, bastará con HTML y CSS puros, pero esto impide una colaboración más amplia en equipo; Además, ningún desarrollador quiere verse obligado a recibir actualizaciones de contenido a perpetuidad.
Entonces, ¿qué sucede cuando un nuevo socio no técnico necesita obtener acceso de edición? Podría ser un diseñador, un gerente de producto, una persona de marketing, un ejecutivo de una empresa o incluso un cliente final.
Para eso sirve un buen sistema de gestión de contenidos, ¿verdad? Quizás algo como WordPress. Pero esto tiene sus propias desventajas: es una nueva plataforma para que su equipo haga malabarismos, una nueva interfaz para aprender y un nuevo vector para posibles atacantes. Requiere crear plantillas, un formato con sintaxis e idiosincrasia propias. Es posible que sea necesario examinar, instalar y configurar complementos personalizados o de terceros para casos de uso únicos, y cada uno de ellos es otra fuente de complejidad, fricción, deuda técnica y riesgo. La sobrecarga de toda esta configuración puede terminar obstaculizando su tecnología de una manera contraproducente para el propósito real del sitio web.
¿Qué pasaría si pudiéramos extraer contenido de donde ya está? A eso nos referimos aquí. Muchos de los lugares donde trabajó utilizan Google Drive para organizar y compartir archivos, y eso incluye cosas como borradores de contenido de blogs y páginas de destino. ¿Podríamos utilizar la API de Google Drive para importar un documento de Google directamente a un sitio como HTML sin formato, con una simple solicitud REST?
¡Por supuesto que podemos! Así es como lo hicimos donde trabajo.
Lo que necesitas
Sólo algunas cosas que quizás quieras comprobar mientras comenzamos:
- repositorio de GitHub
- paquete de mnp
- imagen acoplable
- Demostración de Heroku
Autenticar con la API de Google Drive
El primer paso es establecer una conexión con la API de Google Drive, y para ello necesitaremos realizar algún tipo de autenticación. Ese es un requisito para utilizar la API de Drive incluso si los archivos en cuestión se comparten públicamente (con la opción “compartir mediante enlace” activada). Google admite varios métodos para hacer esto. El más común es OAuth, que muestra al usuario una pantalla con la marca Google que dice: “[Tal y tal aplicación] quiere acceder a su Google Drive” y espera el consentimiento del usuario; no es exactamente lo que necesitamos aquí, ya que Me gustaría acceder a los archivos en una única unidad central, en lugar de la unidad del usuario. Además, es un poco complicado proporcionar acceso sólo a archivos o carpetas concretas. El https://www.googleapis.com/auth/drive.readonlyalcance que podríamos utilizar se describe como:
Vea y descargue todos sus archivos de Google Drive.
Eso es exactamente lo que dice en la pantalla de consentimiento. Esto es potencialmente alarmante para un usuario y, más concretamente, es una posible debilidad de seguridad en cualquier cuenta central de desarrollador/administrador de Google que gestione el contenido del sitio web; todo lo que pueden acceder se exponen a través del backend CMS del sitio, incluidos sus propios documentos y todo lo que se comparte con ellos. ¡No es bueno!
Ingrese a la “Cuenta de servicio”
En su lugar, podemos hacer uso de un método de autenticación un poco menos común: una cuenta de servicio de Google. Piense en una cuenta de servicio como una cuenta ficticia de Google utilizada exclusivamente por API y bots. Sin embargo, se comporta como una cuenta de Google de primera; tiene su propia dirección de correo electrónico, sus propios tokens de autenticación y sus propios permisos. La gran ventaja aquí es que ponemos los archivos a disposición de esta cuenta de servicio ficticia como cualquier otro usuario: compartiendo el archivo con la dirección de correo electrónico de la cuenta de servicio, que se parece a esto:
google-drive-cms-example@npm-drive-cms.iam.gserviceaccount.comCuando vamos a mostrar un documento o una hoja en el sitio web, simplemente presionamos el botón “Compartir” y pegamos esa dirección de correo electrónico. Ahora la cuenta de servicio puede ver solo los archivos o carpetas que hemos compartido explícitamente con ella, y ese acceso se puede modificar o revocar en cualquier momento. ¡Perfecto!
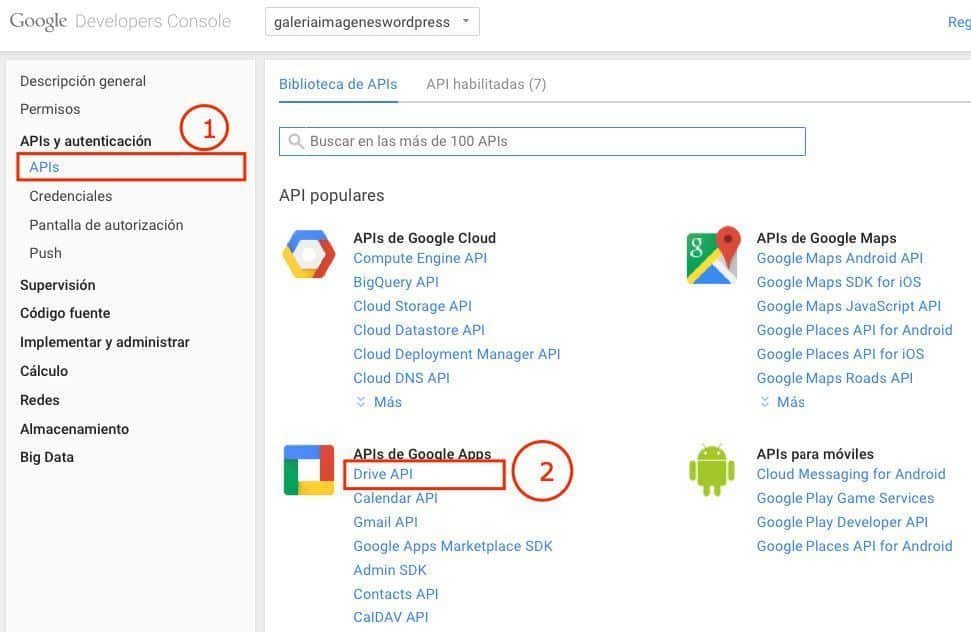
Creando una cuenta de servicio
Se puede crear una cuenta de servicio (gratis) desde Google Cloud Platform Console. Ese proceso está bien documentado en los recursos para desarrolladores de Google y, además, se describe paso a paso en detalle en el repositorio complementario de este artículo en GitHub. En aras de la brevedad, avanzaremos hasta inmediatamente después de una autenticación exitosa de una cuenta de servicio.
La API de Google Drive
Ahora que estamos dentro, estamos listos para comenzar a experimentar con lo que la API de Drive es capaz de hacer. Podemos comenzar desde una versión modificada del ejemplo de inicio rápido de Node.js, ajustada para usar nuestra nueva cuenta de servicio en lugar del cliente OAuth. Esto se maneja en los primeros métodos que driveAPI.jsestamos construyendo para manejar todas nuestras interacciones con la API. La diferencia clave con la muestra de Google está en el authorize()método, donde utilizamos una instancia de jwtClienten lugar de la oauthClientutilizada en la muestra de Google:
authorize(credentials, callback) { const { client_email, private_key } = credentials; const jwtClient = new google.auth.JWT(client_email, null, private_key, SCOPES) // Check if we have previously stored a token. fs.readFile(TOKEN_PATH, (err, token) = { if (err) return this.getAccessToken(jwtClient, callback); jwtClient.setCredentials(JSON.parse(token.toString())); console.log('Token loaded from file'); callback(jwtClient); });}Node.js frente al lado del cliente
Una nota más sobre la configuración aquí: este código está diseñado para ser invocado desde el código Node.js del lado del servidor. Esto se debe a que las credenciales del cliente para la cuenta de servicio deben mantenerse en secreto y no exponerse a los usuarios de nuestro sitio web. Se guardan en un credentials.jsonarchivo en el servidor y se cargan fs.readFiledentro de Node.js. También figura en la lista .gitignorepara mantener las claves confidenciales fuera del control de fuente.
Buscando un documento
Una vez preparado el escenario, cargar HTML sin formato desde un documento de Google se vuelve bastante sencillo. Un método como este devuelve una Promesa de una cadena HTML:
getDoc(id, skipCache = false) { return new Promise((resolve, reject) = { this.drive.files.export({ fileId: id, mimeType: "text/html", fields: "data", }, (err, res) = { if (err) return reject('The API returned an error: ' + err); resolve({ html: this.rewriteToCachedImages(res.data) }); // Cache images this.cacheImages(res.data); }); });}El punto final Drive.Files.export hace todo el trabajo por nosotros aquí. Lo idque estamos pasando es justo lo que aparece en la barra de direcciones de su navegador cuando abre el documento, que se muestra inmediatamente después https://docs.google.com/document/d/.
Observe también las dos líneas sobre el almacenamiento en caché de imágenes; Esta es una consideración especial que omitiremos por ahora y que revisaremos en detalle en la siguiente sección.
A continuación se muestra un ejemplo de un documento de Google que se muestra externamente como HTML utilizando este método.
Buscando una hoja
Obtener Google Sheets es casi tan fácil con Spreadsheets.values.get. Ajustamos un poco el objeto de respuesta para convertirlo en una matriz JSON simplificada, etiquetada con encabezados de columna de la primera fila de la hoja.
getSheet(id, range) { return new Promise((resolve, reject) = { this.sheets.spreadsheets.values.get({ spreadsheetId: id, range: range, }, (err, res) = { if (err) return reject('The API returned an error: ' + err); // console.log(res.data.values); const keys = res.data.values[0]; const transformed = []; res.data.values.forEach((row, i) = { if(i === 0) return; const item = {}; row.forEach((cell, index) = { item[keys[index]] = cell; }); transformed.push(item); }); resolve(transformed); }); });}El idparámetro es el mismo que para un documento, y el nuevo rangeparámetro aquí se refiere a un rango de celdas para recuperar valores, en notación de Hojas A1.
Ejemplo : esta hoja se lee y analiza para representar HTML personalizado en esta página.
…¡y más!
Estos dos puntos finales ya lo llevan muy lejos y forman la columna vertebral de un CMS personalizado para un sitio web. Pero, de hecho, sólo aprovecha la superficie del potencial de Drive para la gestión de contenidos. También es capaz de:
- enumerar todos los archivos en una carpeta determinada y mostrarlos en un menú,
- importar medios complejos desde una presentación de Google Slides, y
- descargar y almacenar en caché archivos personalizados.
Los límites únicos aquí son su creatividad y las limitaciones de la API de Drive completa documentada aquí.
Almacenamiento en caché
Mientras juegas con los distintos tipos de consultas que admiten Drive API, es posible que termines recibiendo el mensaje de error “Límite de tasa de usuario excedido”. Es bastante fácil alcanzar este límite mediante repetidas pruebas de prueba y error durante la fase de desarrollo y, a primera vista, parece que representaría un obstáculo duro para nuestra estrategia Google Drive-CMS.
Aquí es donde entra en juego el almacenamiento en caché: cada vez que recuperamos una nueva versión de cualquier archivo en Drive.
lo almacenamos en caché localmente (también conocido como del lado del servidor, dentro del proceso Node.js). Una vez hecho esto, solo necesitamos verificar la versión de cada archivo. Si nuestro caché está desactualizado, recuperamos la versión más reciente del archivo correspondiente, pero esa solicitud solo ocurre una vez por versión de archivo, en lugar de una vez por solicitud del usuario.
En lugar de escalar según la cantidad de personas que usan el sitio web, ahora podemos escalar según la cantidad de actualizaciones/ediciones en Google Drive como nuestro factor limitante. Según los límites de uso actuales de Drive en una cuenta de nivel gratuito, podríamos admitir hasta 300 solicitudes de API por minuto. El almacenamiento en caché debería mantenernos dentro de este límite y podría optimizarse aún más agrupando múltiples solicitudes por lotes.
Manejo de imágenes
El mismo método de almacenamiento en caché se aplica a las imágenes incrustadas en Google Docs. El getDocmétodo analiza la respuesta HTML para cualquier URL de imagen y realiza una solicitud secundaria para descargarlas (o las recuperan directamente del caché si ya están allí). Luego reescribe la URL original en HTML. El resultado es ese HTML estático; Nunca utilizamos enlaces directos a CDN de imágenes de Google. Cuando llega al navegador, las imágenes ya se han almacenado previamente en caché.
Respetuoso y receptivo
El almacenamiento en caché garantiza dos cosas: en primer lugar, que respetamos los límites de uso de la API de Google y que realmente utilizamos Google Drive como interfaz para editar y administrar archivos (para qué está diseñada la herramienta), en lugar de filtrarlo para obtener ancho de banda gratuito. y espacio de almacenamiento. Mantiene la interacción de nuestro sitio web con las API de Google al mínimo necesario para actualizar el caché según sea necesario.
El otro beneficio es uno que disfrutarán los usuarios de nuestro sitio web: un sitio web responsivo con tiempos de carga mínimos. Dado que los documentos de Google almacenados en caché se almacenan como HTML estático en nuestro propio servidor, podemos recuperarlos inmediatamente sin esperar a que se complete una solicitud REST de un tercero, manteniendo los tiempos de carga del sitio web al mínimo.
Envoltura en Express
Dado que todos estos retoques se han realizado en Node.js del lado del servidor, necesitamos una forma para que las páginas de nuestros clientes interactúen con las API. Al incluirlo DriveAPIen su propio servicio REST, podemos crear un servicio intermediario/proxy que abstrae toda la lógica del almacenamiento en caché/obtención de nuevas versiones, mientras mantiene seguras las credenciales de autenticación confidenciales en el lado del servidor.
Una serie de expressrutas, o el equivalente en su servidor web favorito, funcionará, con una serie de rutas como esta:
const driveAPI = new (require('./driveAPI'))();const express = require('express');const API_VERSION = 1;const router = express.Router();router.route('/getDoc').get((req, res) = { console.log('GET /getDoc', req.query.id); driveAPI.getDoc(req.query.id) .then(data = res.json(data)) .catch(error = { console.error(error); res.sendStatus(500); });});// Other routes included here (getSheet, getImage, listFiles, etc)...app.use(`/api/v${API_VERSION}`, router);Vea el archivo express.js completo en el repositorio complementario.
Bonificación: implementación de Docker
Para la implementación en producción, podemos ejecutar el servidor Express junto con su servidor web estático existente. O, si es conveniente, podríamos involucrarlo fácilmente en una imagen de Docker:
FROM node:8# Create app directoryWORKDIR /usr/src/app# Install app dependencies# A wildcard is used to ensure both package.json AND package-lock.json are copied# where available (npm@5+)COPY package*.json ./RUN npm install# If you are building your code for production# RUN npm ci --only=production# Bundle app sourceCOPY . .CMD [ "node", "express.js" ]…o utilice esta imagen prediseñadas publicada en Docker Hub.
Bonificación 2: NGINX Google OAuth
Si su sitio web es público (accesible para cualquier persona en Internet), ¡ya está! Pero para nuestros propósitos donde trabajo en Motorola, estamos publicando un sitio de documentación interna que necesita seguridad adicional. Eso significa que Link Sharing está desactivado en todos nuestros Google Docs (también estaban almacenados en un Google Team Drive aislado y dedicado, separado de todo el resto del contenido de la empresa).
Manejamos esta capa adicional de seguridad lo antes posible a nivel de servidor, utilizando NGINX para interceptar y realizar proxy inverso de todas las solicitudes incluso antes de que lleguen al servidor Express oa cualquier contenido estático alojado en el sitio web. Para ello, utilizamos la excelente imagen Docker de Cloudflare para presentar una pantalla de inicio de sesión de Google a todos los empleados que acceden a cualquier recurso o punto final del sitio web (tanto el servidor Drive API Express como el contenido estático que lo acompaña) . Se integra perfectamente con la cuenta corporativa de Google y el inicio de sesión única que ya tienen, ¡no se necesita una cuenta adicional!
Conclusión
Todo lo que acabamos de cubrir en este artículo es exactamente lo que hemos hecho donde trabajo. Es una arquitectura de administración de contenidos liviana, flexible y descentralizada, en la que los datos sin procesar residen en Google Drive, donde nuestro equipo ya trabaja, utilizando una interfaz de usuario que ya es familiar para todos. Todo se integra en la interfaz del sitio web, que conserva la flexibilidad total de HTML y CSS puros en términos de control sobre la presentación y con restricciones arquitectónicas mínimas. Un poco de trabajo extra por su parte, el desarrollador, crea una experiencia prácticamente perfecta tanto para sus colaboradores que no son desarrolladores como para sus usuarios finales.
¿Este tipo de cosas funcionará para todos?
Por supuesto que no. Diferentes sitios tienen diferentes necesidades. Pero si tuviera que armar una lista de casos de uso sobre cuándo usar Google Drive como CMS, se vería así:
- Un sitio interno con entre unos cientos y unos miles de usuarios diarios : si esta hubiera sido la página principal del sitio web global de la empresa, incluso una sola solicitud de metadatos de la versión del archivo por usuario podría acercarse al límite de uso de Drive API. Otras técnicas podrían ayudar a mitigar esto, pero es la mejor opción para sitios web pequeños y medianos.
- Una aplicación de una sola página : esta configuración nos ha permitido consultar los números de versión de cada fuente de datos en una única solicitud REST, una vez por sesión, en lugar de una vez por página. Una aplicación que no sea de una sola página podría utilizar el mismo enfoque, tal vez incluso haciendo uso de cookies o almacenamiento local para realizar la misma consulta de versión “una vez por visita”, pero nuevamente, requeriría un poco de trabajo extra.
- Un equipo que ya utiliza Google Drive . Quizás lo más importante de todo es que nuestros colaboradores quedaron gratamente sorprendidos de poder contribuir al sitio web utilizando una cuenta y un flujo de trabajo al que ya tenían acceso y con los que se sentían cómodos, incluidas todas las mejoras de la experiencia WYSIWYG de Google. . , potente gestión de acceso, y el resto.
Deja un comentario